Fitting Models with Likelihood!
![]()
Outline
- Review of Likelihood
- Comparing Models with Likelihood
- Linear Regression with Likelihood
Deriving Truth from Data
- Frequentist Inference: Correct conclusion drawn from repeated experiments
- Uses p-values and CIs as inferential engine
- Likelihoodist Inference: Evaluate the weight of evidence for different hypotheses
- Derivative of frequentist mode of thinking
- Uses model comparison (sometimes with p-values…)
- Bayesian Inference: Probability of belief that is constantly updated
- Uses explicit statements of probability and degree of belief for inferences
Likelihood: how well data support a given hypothesis.
Note: Each and every parameter choice IS a hypothesis
Likelihood Defined
\[\Large L(H | D) = p(D | H)\]
Where the D is the data and H is the hypothesis (model) including a both a data generating process with some choice of parameters (aften called \(\theta\)). The error generating process is inherent in the choice of probability distribution used for calculation.
Example of Maximum Likelihood Fit
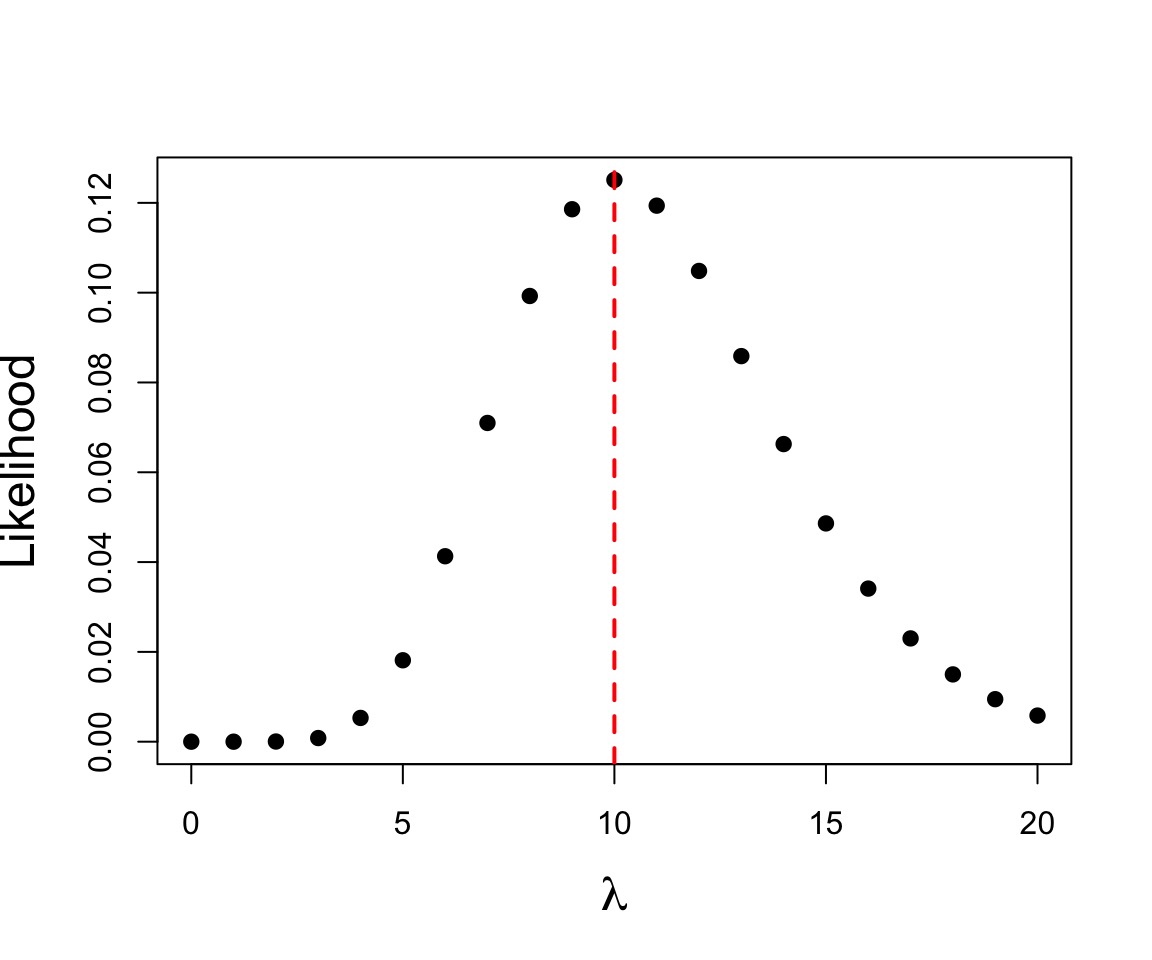
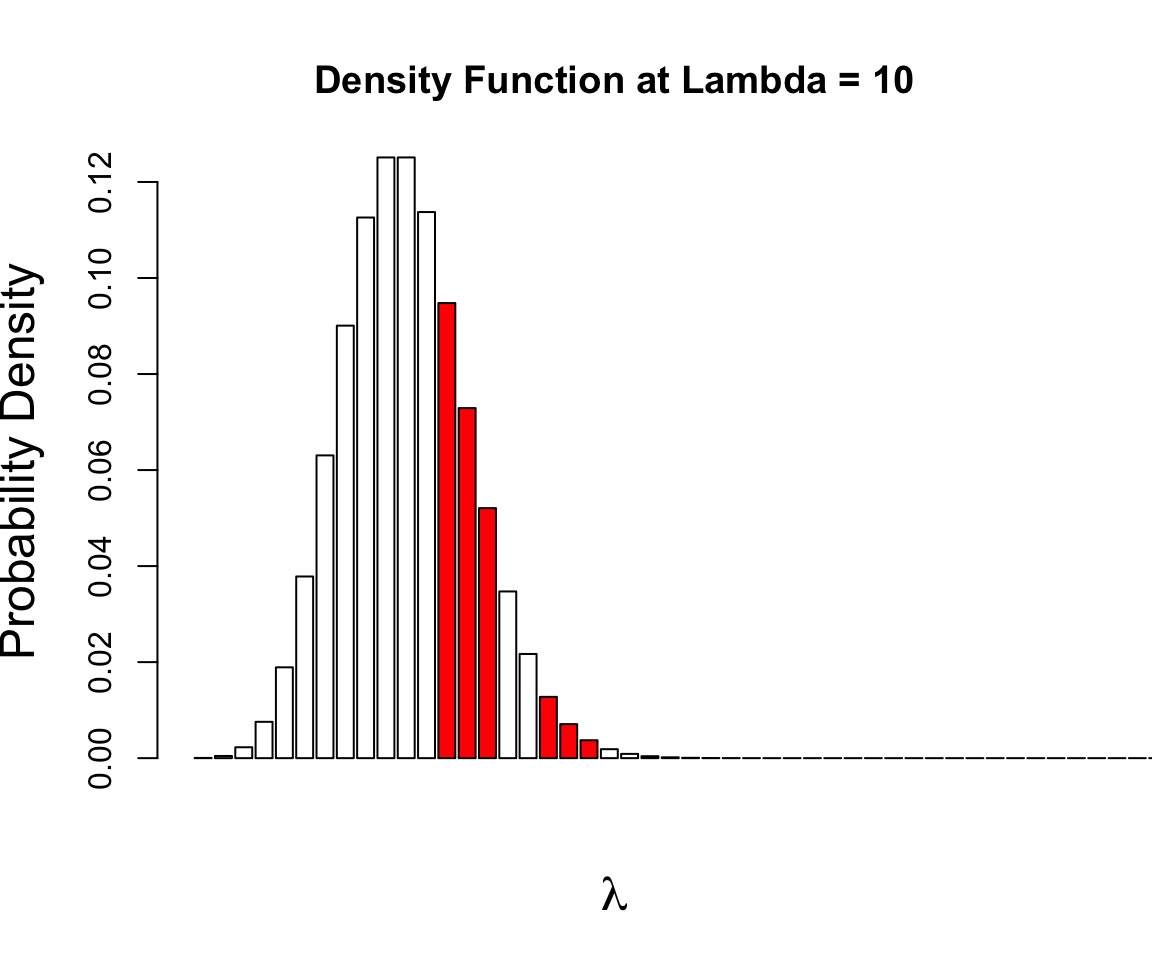
Let’s say we have counted 10 individuals in a plot. Given that the population is Poisson distributed, what is the value of \(\lambda\)?
$$p(x) = \frac{\lambda^{x}e^{-\lambda}}{x!}$$
where we search all possible values of λ
Likelihood Function
\[\Large p(x) = \frac{\lambda^{x}e^{-\lambda}}{x!}\]
- This is a Likelihood Function for one sample
- It is the Poisson Probability Density function
- \(Dpois = \frac{\lambda^{x}e^{-\lambda}}{x!}\)
What is the probability of the data given the parameter?
p(a and b) = p(a)p(b)
$$p(D | \theta) = \prod_{i=1}^n p(d_{i} | \theta)$$
$$ = \prod_{i=1}^n \frac{\theta^{x_i}e^{-\theta}}{x_!}$$
Outline
- Review of Likelihood
- Comparing Models with Likelihood
- Linear Regression with Likelihood
Can Compare p(data | H) for alternate Parameter Values
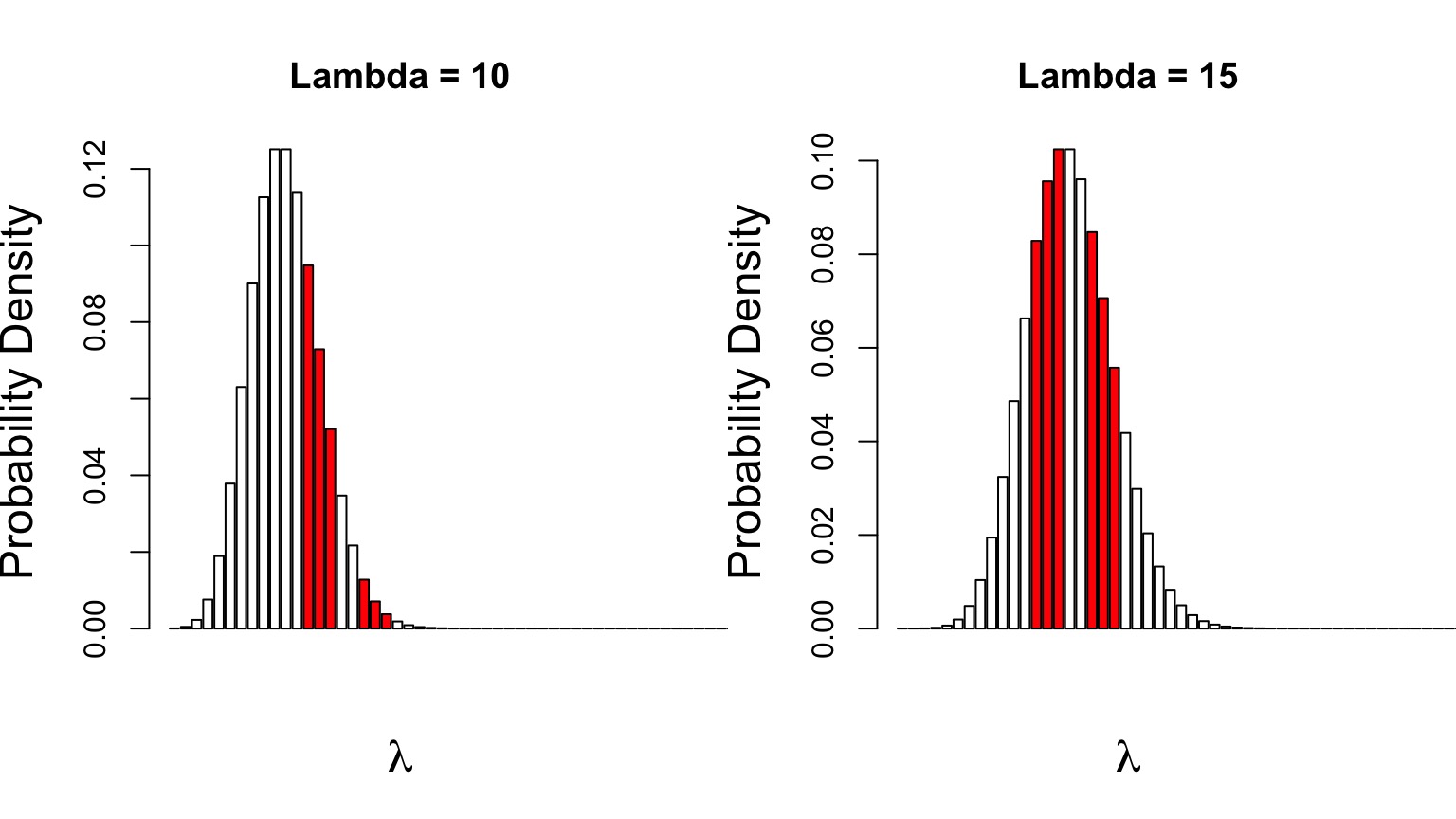
Compare \(p(D|\theta_{1})\) versus \(p(D|\theta_{2})\)
Likelihood Ratios
\[\LARGE G = \frac{L(H_1 | D)}{L(H_2 | D)}\]
- G is the ratio of Maximum Likelihoods from each model
- Used to compare goodness of fit of different models/hypotheses
- Most often, \(\theta\) = MLE versus \(\theta\) = 0
- \(-2 log(G)\) is \(\chi^2\) distributed
Likelihood Ratio Test
- A new test statistic: \(D = -2 log(G)\)
- \(= 2 [Log(L(H_2 | D)) - Log(L(H_1 | D))]\)
- It’s \(\chi^2\) distributed!
- DF = Difference in # of Parameters
- If \(H_1\) is the Null Model, we have support for our alternate model
Likelihood Ratio at Work
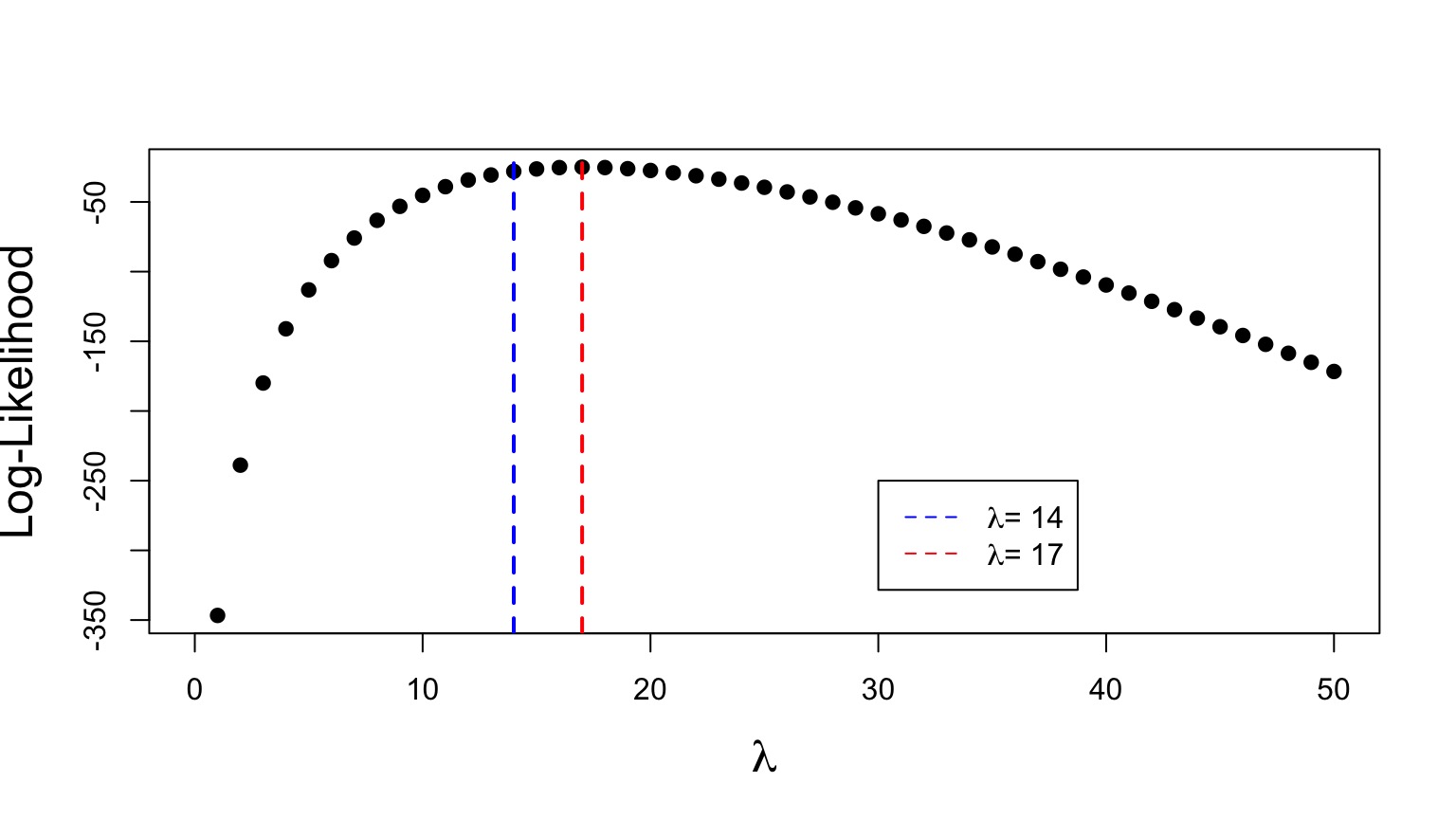
\[G = \frac{L(\lambda = 14 | D)}{L(\lambda = 17 | D)}\]
=0.0494634
Likelihood Ratio Test at Work
\[D = 2 [Log(L(\lambda = 14 | D)) - Log(L(\lambda = 17 | D))]\] =6.0130449 with 1DF
p =0.01
Outline
- Review of Likelihood
- Comparing Models with Likelihood
- Linear Regression with Likelihood
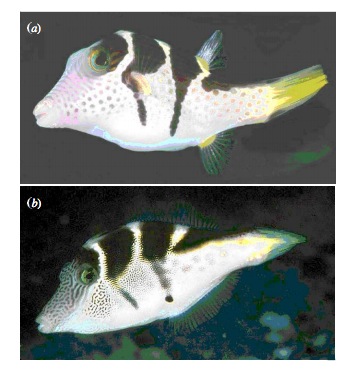
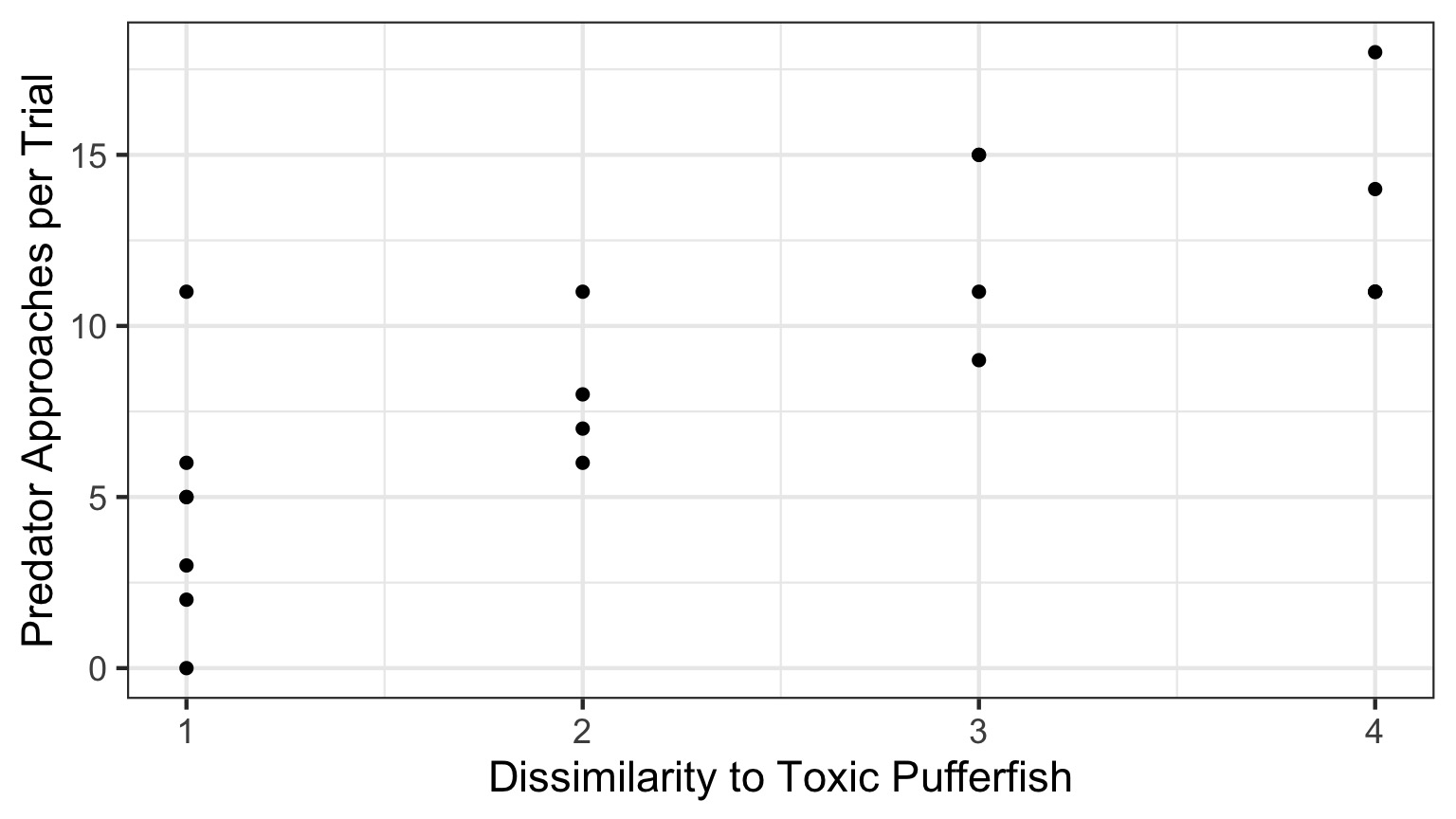
Putting Likelihood Into Practice with Pufferfish
- Pufferfish are toxic/harmful to predators
- Batesian mimics gain protection from predation
- Evolved response to appearance?
- Researchers tested with mimics varying in toxic pufferfish resemblance
Does Resembling a Pufferfish Reduce Predator Visits?
The Steps of Statistical Modeling
- What is your question?
- What model of the world matches your question?
- Build a test
- Evaluate test assumptions
- Evaluate test results
- Visualize
The World of Pufferfish
Data Generating Process:
\[Visits \sim Resemblance\]
Assume: Linearity (reasonable first approximation)
Error Generating Process:
Variation in Predator Behavior
Assume: Normally distributed error (also reasonable)
Quantiative Model of Process Using Likelihood
Likelihood:
\(Visits_i \sim \mathcal{N}(\hat{Visits_i}, \sigma)\)
Data Generating Process:
\(\hat{Visits_i} = \beta_{0} + \beta_{1} Resemblance_i\)
Likelihood Function for Linear Regression
Will often see:
\(\large L(\theta | D) = \prod_{i=1}^n p(y_i\; | \; x_i;\ \beta_0, \beta_1, \sigma)\)
Likelihood Function for Linear Regression
\[L(\theta | Data) = \prod_{i=1}^n \mathcal{N}(Visits_i\; |\; \beta_{0} + \beta_{1} Resemblance_i, \sigma)\]
where \(\beta_{0}, \beta_{1}, \sigma\) are elements of \(\theta\)
Quantiative Model of Process Using Likelihood
Likelihood:
\(Visits_i \sim \mathcal{N}(\hat{Visits_i}, \sigma)\)
Data Generating Process:
\(\hat{Visits_i} = \beta_{0} + \beta_{1} Resemblance_i\)
But - What do the Likelihood Profiles Look Like?
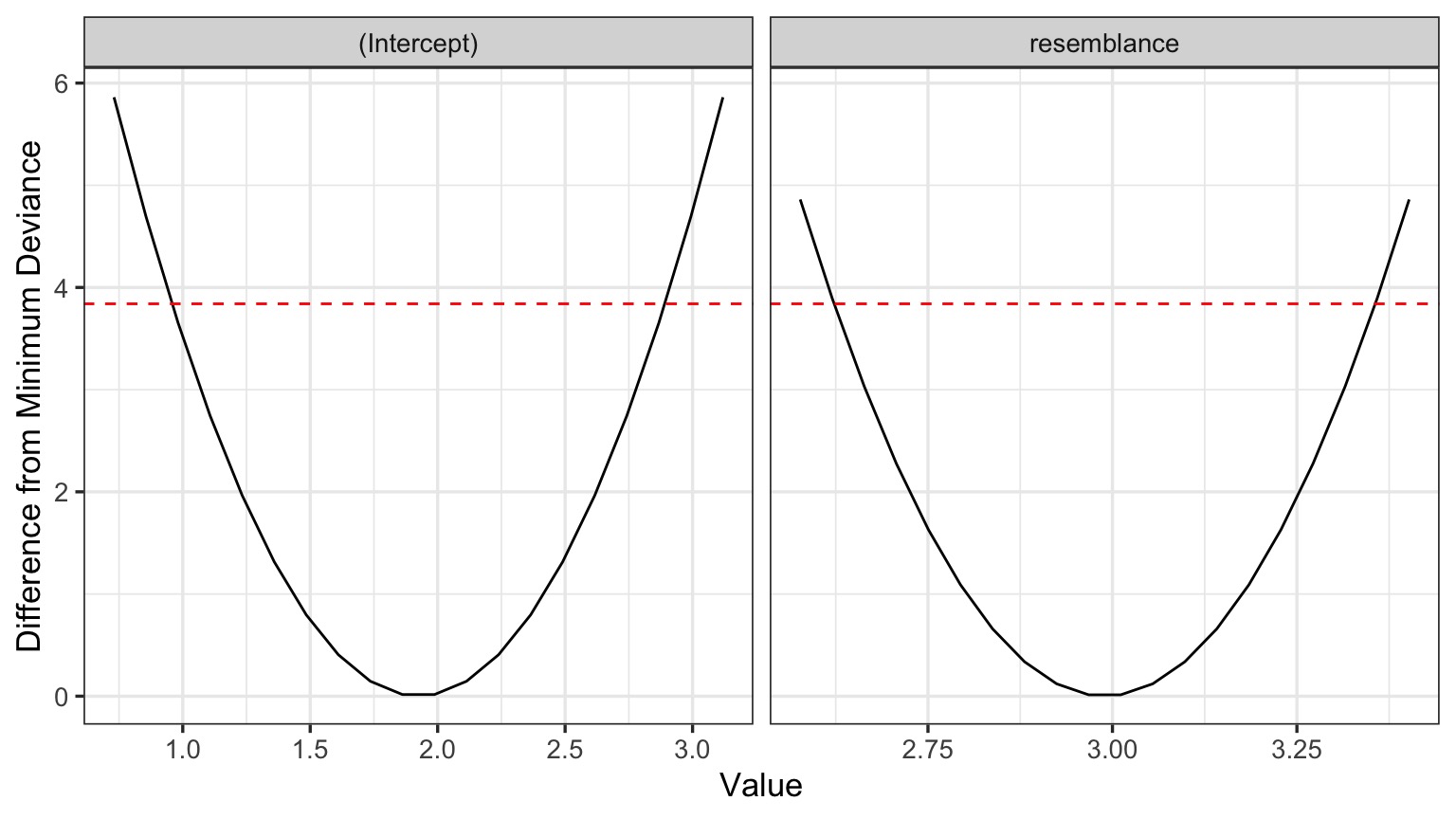
Are these nice symmetric slices?
Sometimes Easier to See with a Straight Line
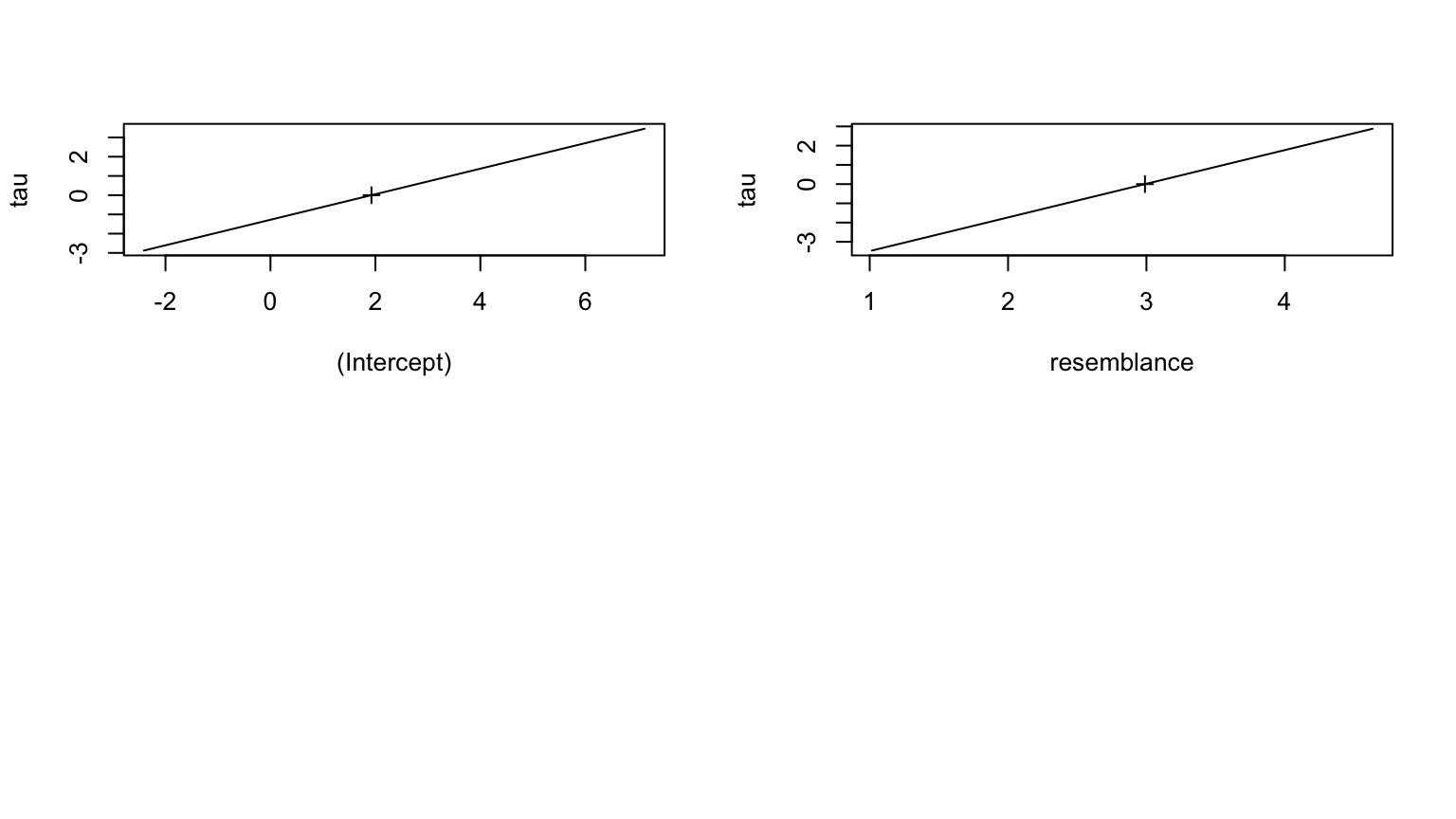
tau = signed sqrt of difference from deviance
Evaluate Coefficients
|
term
|
estimate
|
std.error
|
statistic
|
p.value
|
|
(Intercept)
|
1.925
|
1.506
|
1.278
|
0.218
|
|
resemblance
|
2.989
|
0.571
|
5.232
|
0.000
|
Test Statistic is a Wald Z-Test Assuming a well behaved quadratic Confidence Interval
Confidence Intervals
Quadratic Assumption
|
|
2.5 %
|
97.5 %
|
|
(Intercept)
|
-1.028
|
4.877
|
|
resemblance
|
1.870
|
4.109
|
Spline Fit to Likelihood Surface
|
|
2.5 %
|
97.5 %
|
|
(Intercept)
|
-1.028
|
4.877
|
|
resemblance
|
1.870
|
4.109
|
To test the model, need an alternate hypothesis
Put it to the Likelihood Ratio Test!
Analysis of Deviance Table
Model 1: predators ~ 1
Model 2: predators ~ resemblance
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 19 422.95
2 18 167.80 1 255.15 1.679e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Compare to Linear Regression
Likelihood:
|
term
|
estimate
|
std.error
|
statistic
|
p.value
|
|
(Intercept)
|
1.925
|
1.506
|
1.278
|
0.218
|
|
resemblance
|
2.989
|
0.571
|
5.232
|
0.000
|
Least Squares
|
term
|
estimate
|
std.error
|
statistic
|
p.value
|
|
(Intercept)
|
1.925
|
1.506
|
1.278
|
0.218
|
|
resemblance
|
2.989
|
0.571
|
5.232
|
0.000
|
Compare to Linear Regression: F and Chisq
Likelihood:
|
Resid. Df
|
Resid. Dev
|
Df
|
Deviance
|
Pr(>Chi)
|
|
19
|
422.950
|
|
|
|
|
18
|
167.797
|
1
|
255.153
|
0
|
Least Squares
|
|
Df
|
Sum Sq
|
Mean Sq
|
F value
|
Pr(>F)
|
|
resemblance
|
1
|
255.1532
|
255.153152
|
27.37094
|
5.64e-05
|
|
Residuals
|
18
|
167.7968
|
9.322047
|
|
|